
Ahora se sabe que una nueva palabra de moda está surgiendo en Internet y que tal vez esté reemplazando, o añadiendo, a la antigua «computación en la nube».
Big Data.
Los dos términos, que han sido objeto de bombardeo mediático en Internet, son también dos términos que están muy estrechamente vinculados entre sí, como queremos demostrar a continuación. Como también queremos mostrar cómo el mundo del BigData también está profundamente ligado al mundo OpenSource, veamos, por ejemplo, el vínculo entre Cloud Computing y OpenSource, en nuestra antigua nota.
Definición
Empecemos por algunas definiciones de BigData, para tratar de frenar los habituales errores periodísticos sensacionalistas, o intencionados con fines de marketing, a los que nos hemos acostumbrado sobradamente en cuanto al Cloud Computing. ¿Existe alguna definición oficial?
Citamos a WikiPedia, Gartner, IBM y la Universidad de Villanova en Tampa (Florida) y más adelante en el NIST:
Gartner – tomado del glosario
IBM , y también sugiero esta infografía suya de las 4V
Por ello, todo el mundo parece coincidir en definir el big data como «una colección de datos tan grande y compleja que requiere de herramientas diferentes a las tradicionales para ser analizada y visualizada». Entonces comienzan algunas diferencias:
Todo el mundo está de acuerdo en que «los datos provendrían potencialmente de fuentes heterogéneas», y aquí están los que argumentan que todos son «datos estructurados» y los que, en cambio, también les añaden «datos no estructurados».
Vayamos a las dimensiones que deben tener estos datos para llamarlos BigData, aquí obviamente hay discordancia y wikipedia en inglés argumenta con razón que el tamaño del bigdata está en constante movimiento, no podía ser de otra manera considerando los muchos estudios que cada año analizan el crecimiento de los datos producidos a nivel mundial. En 2012, se hablaba de un rango de decenas de terabytes a varios petabytes, para cada conjunto de datos, mientras que ahora estamos hablando de zettabytes (miles de millones de terabytes).
En cuanto al fondo, citamos este provocador artículo de Marco Russo enviado a Luca De Biase y publicado por él en su blog.
Todo el mundo está de acuerdo en las 3 V sobre las características del Big Data:
- Volumen: capacidad de adquirir, almacenar y acceder a grandes volúmenes de datos;
- Velocidad: capacidad de realizar análisis de datos en tiempo real o casi real;
- Variedad: se refiere a los diversos tipos de datos, provenientes de diferentes fuentes.
Y algunos hablan de una V de 4′:
- Veracidad: es decir, la calidad de los datos entendida como el valor de la información que se puede extraer
Pero, ¿qué está haciendo el NIST con respecto a la definición de Big Data? Sabemos que el NIST se mueve lenta y engorrosamente, esto lo aprendimos de los muchos meses o más bien años en los que la definición de Cloud Computing estuvo permanentemente en borrador, y comenzaron a trabajar en ella desde 2008.
Pues bien, el NIST empieza a moverse cuando el gobierno de EE.UU. decide destinar 200 millones de dólares en la Iniciativa BigData, por lo que se pone en marcha el NIST BigData WorkShop y un Grupo de Trabajo abierto a todos, como se hizo para la definición y todos los documentos relacionados con el término Cloud Computing
Ecosistema
Para mostrar el tamaño del ecosistema global que gira en torno a este término, veamos tres infografías de Bloomberg, Forbes y Capgemini respectivamente.


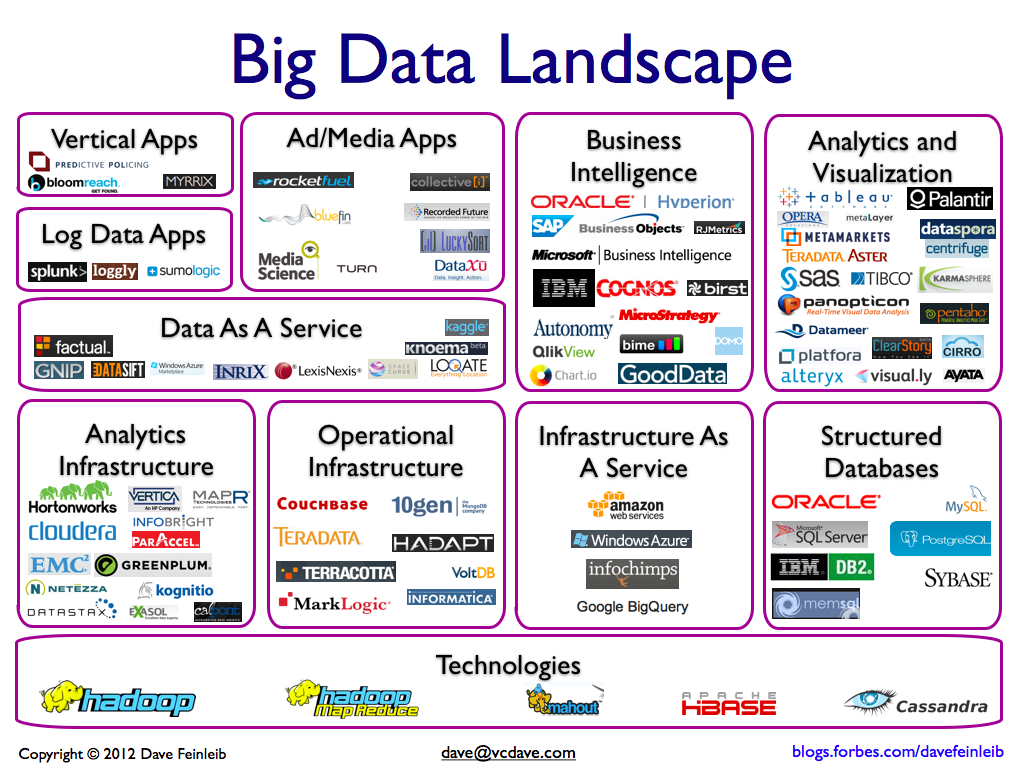

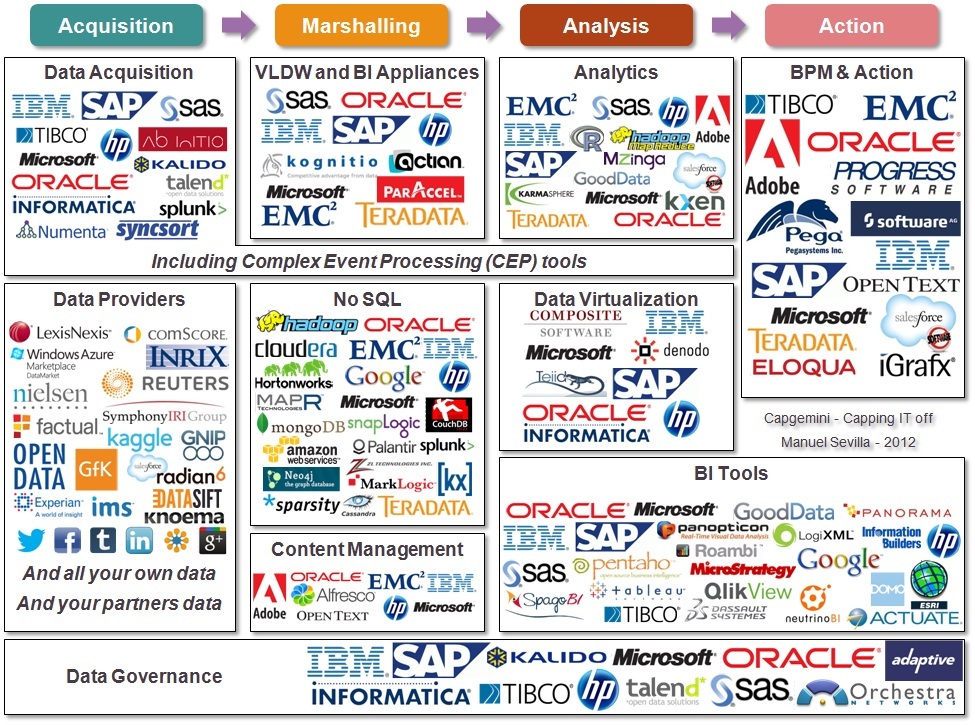
Ya a partir de estas tres infografías es evidente cómo las soluciones OpenSource se utilizan masivamente en el ecosistema BigData, incluso Forbes pone solo software OpenSource en las tecnologías.
Dimensión
Echemos un vistazo al mercado y al crecimiento en torno a este ecosistema de BigData
Según Gartner (datos de 2012), Big Data impulsará 28 mil millones de dólares de gasto en TI , Big Data crea grandes empleos: 4,4 millones de puestos de trabajo de TI en todo el mundo para soportar Big Data para 2015
Y ahora vamos a disfrutar de estas dos infografías, una de Asigra y otra de IBM, que es muy activa en el mundo del BigData:

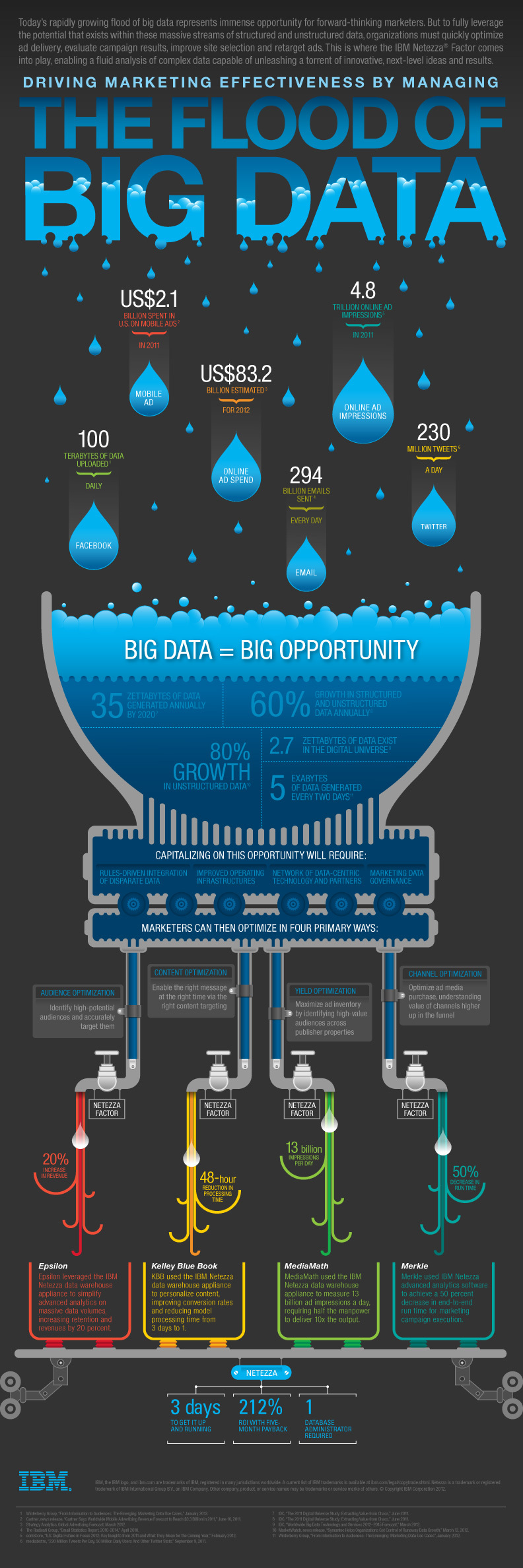


{kind=link}
En resumen, el mercado de Big Data requiere básicamente algunas cosas:
- Sistemas de almacenamiento de big data, pero realmente grandes
- Gran capacidad de cómputo paralelo
- Personal cualificado (Data Analyst, Data Scientist) capaz de «olfatear» resultados interesantes mediante el análisis de grandes cantidades de datos aparentemente no relacionados.
- Software de adquisición continua de datos, software de análisis de datos y software de representación visual de datos
Oportunidad
El BigData, en mi opinión, es una gran oportunidad para las grandes empresas de HW y SW IT (IBM, HP, EMC, Oracle, etc) ya que despierta las necesidades de las empresas hacia la compra de HW en lugar del uso de la Nube Pública. También existe una creciente necesidad de software simple, dedicado y personalizado para el análisis de datos. Por supuesto, en muchos casos se podría mantener y procesar en Cloud Providers, y esto es lo que líderes del mercado como AWS llevan tiempo permitiendo hacer, con DynamoDB, RedShift, Elastic MapReduce, pero mantener petabytes o zettabytes (si estos son los valores a los que tenemos que referirnos para hablar de Bigdata) en la Nube cuesta mucho e incluso creo que puede ser conveniente mantener tu propia infraestructura. Es diferente si tenemos unos pocos terabytes de datos sobre los que queremos hacer DataAnalysis, y creo que este es el escenario más general, donde los servicios de una nube pública como AWS se vuelven realmente competitivos.
Recientemente, las grandes empresas de TI han abierto muchas oportunidades para las empresas, startups y el mundo de la investigación relacionada con Big Data, por ejemplo EMC anuncia el kit Hadoop Starter 2.0, o Microsoft que ofrece Hadoop en la nube de Azure, o SAS se alía con SAP en la plataforma Hana, también SAP HANA onDemand en AWS, o INTEL y AWS que ofrecen pruebas y pruebas gratuitas, en resumen, hay algo para todos, es una verdadera explosión para la economía de TI.
Código abierto y computación en la nube
Sobre BigData y Cloud Computing en la práctica ya hemos respondido, las posibilidades son muchas, hemos mencionado el líder máximo (AWS) y Azure, ya que ofrece Public Cloud, pero también a Google no le faltan herramientas útiles (BigQuery), por otro lado basta recordar el famoso y ya antiguo BigTable de Google, que se utiliza para su motor de búsqueda.
La Nube Pública, incluso en el caso del Big Data, puede ser muy útil y muy democrática (si no tenemos en cuenta el tamaño de los conjuntos de datos tan bien como lo tendrían las definiciones). Pensemos en la sencillez de no tener que gestionar sistemas de almacenamiento, copias de seguridad, recuperación ante desastres, de no tener que gestionar SW de DataAnalysis (si usamos alguna solución PaaS o SaaS), de la sencillez de poder mantener poca potencia activa durante periodos de no análisis (pagando poco) y de poder instanciar potencia de cálculo solo durante nuestras consultas.
Ahora llegamos a BigData y OpenSource; como hemos podido detectar hasta ahora, un nombre resuena con fuerza en todos los escenarios mencionados hasta ahora, HADOOP.
Hadoop es un marco de software de código abierto (licencia Apache 2.0) para almacenar y procesar grandes cantidades de datos en clústeres de hardware básico; Nació en 2005 de la mano de Doug Cutting y Mike Cafarella y si no recuerdo mal nació como una emulación SW de BigTable de Google, para proyectos de buscadores de la competencia.
De este proyecto han surgido muchas soluciones de almacenamiento distribuido, al igual que muchas soluciones de almacenamiento distribuido. Por ejemplo, Hadoop tiene muchos proyectos secundarios, como:
- HDFS, un sistema de archivos distribuido.
- Cassandra, una base de datos multimaestra escalable sin punto de fallo (utilizada por Facebook).
- HBase, una base de datos distribuida para datos estructurados para tablas muy grandes (miles de millones de filas y millones de columnas).
- Hive, un almacén de datos que permite una fácil consulta y administración de grandes conjuntos de datos que residen en el almacenamiento distribuido.
- Pig, una plataforma para el análisis de grandes conjuntos de datos que consisten en un lenguaje de alto nivel. Los programas pig tienen la característica de poder ejecutarse en paralelo, por lo que permite el análisis de grandes cantidades de datos en poco tiempo.
- Mahout, un proyecto para producir implementaciones escalables de algoritmos de aprendizaje automático centrado principalmente en las áreas de filtrado, agrupación y clasificación colaborativas.
por mencionar los más conocidos en el mundo Hadoop.
Pero el código abierto al servicio del Big Data no se detiene ahí:
- Infinidb, es una base de datos para el almacenamiento de datos. Habilitado para MySQL con tecnología orientada a columnas, está diseñado específicamente para análisis, consultas analíticas, soporte transaccional y cargas de trabajo de carga masiva. También habilitado para Hadoop.
- SciDB es una plataforma de análisis avanzado y gestión de datos todo en uno. Altamente escalable, para análisis complejos con un sistema de versionado de datos, para necesidades comerciales y científicas. Es una plataforma de software capaz de ejecutarse en una red de hardware básico o en la nube.
- OpenTSDB, es una Base de Datos de Series Temporales basada en HBase+Hadoop, es un sistema distribuido para la adquisición y análisis distribuido de grandes conjuntos de datos temporales, como mediciones científicas o meteorológicas.
- RRDTool, me gustaría mencionarlo aunque no debería incluirse en herramientas para BigData, porque no fue creado para trabajar con grandes cantidades de datos, pero es muy adecuado para representaciones gráficas, tiene dimensiones finitas de sus propias series de datos, pero continuamente calcula estadísticas con cada nueva entrada de nuevos datos.
- MySQL para Big Data, MySQL la base de datos por excelencia del mundo abierto, la más utilizada en el mundo, no es menos, aunque la tendencia actual ve un fuerte impulso para el mundo NoSQL, pero MySQL ha tenido características para big data durante mucho tiempo, solo piense en la posibilidad de particionar datos para acelerar las consultas, entonces la escalabilidad de MySQL es conocida por la mayoría.
- Talend dispone de una serie de productos de primera categoría que puede descargar, basando su negocio en el soporte, el asesoramiento, la formación y la certificación.
Aquí puedes encontrar tutoriales recientes que puedes consultar de forma gratuita.
- Scipy, una serie de bibliotecas basadas en Python para matemáticas, ciencias e ingeniería.
- gnuplot, una potente CLI para una variedad de sistemas operativos para representar datos en gráficos potentes y hermosos.
- R, es un entorno de software para el cálculo estadístico y gráficos, vinculado a esta herramienta también encontramos algunos paquetes interesantes de rOpenSci
- mongodb, es la más conocida de las bases de datos NoSQL, altamente escalable, y con características Map/Reduce, es decir, con un modelo de programación para procesar grandes conjuntos de datos en paralelo, con algoritmos distribuidos en clusters.
- Couchdb, creo que se puede decir que es un competidor de MongoDB.
- Neo4j, es una base de datos de grafos escalable, robusta y totalmente ACID.
- Presto es un motor de búsqueda distribuido de código abierto para ejecutar consultas SQL interactivas analíticas en fuentes de datos de todos los tamaños, desde gigabytes hasta petabytes.
Nos detendremos aquí por ahora, pero seguiremos actualizando el artículo.